MyCat分片怎么配置
本篇內容主要講解“MyCat分片怎么配置”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“MyCat分片怎么配置”吧!
10年積累的網站設計制作、成都網站設計經驗,可以快速應對客戶對網站的新想法和需求。提供各種問題對應的解決方案。讓選擇我們的客戶得到更好、更有力的網絡服務。我雖然不認識你,你也不認識我。但先網站設計后付款的網站建設流程,更有灌云免費網站建設讓你可以放心的選擇與我們合作。
MyCat 架構
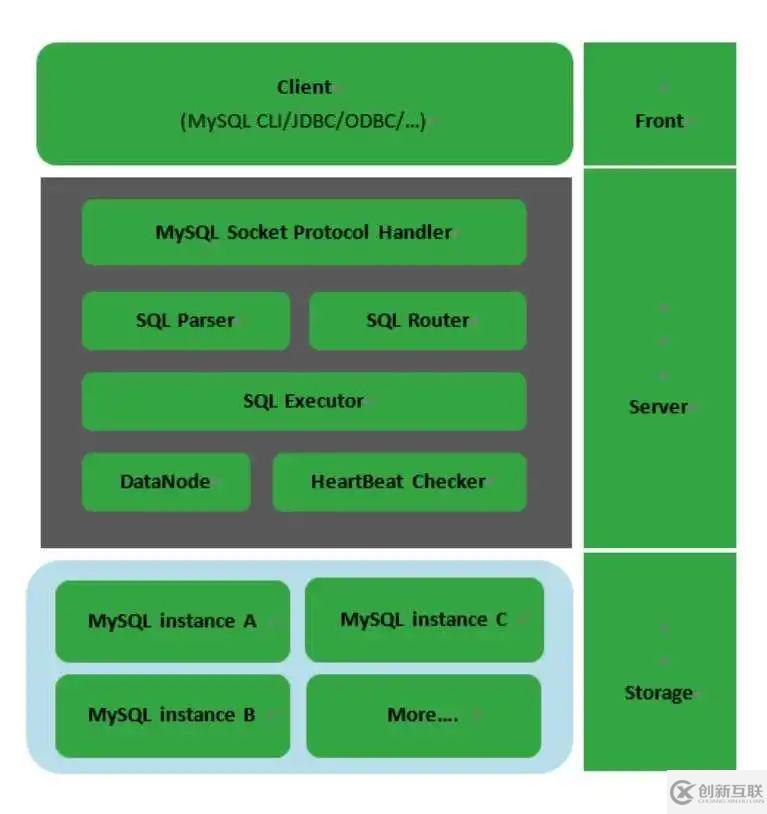
MyCat 核心概念
Schema
Schema:由它指定邏輯數據庫(相當于MySQL的database數據庫)
Table
Table:邏輯表(相當于MySQL的table表)
DataNode
DataNode:真正存儲數據的物理節點
DataHost
DataHost:存儲節點所在的數據庫主機(指定MySQL數據庫的連接信息)
User
User:MyCat的用戶(類似于MySQL的用戶,支持多用戶)
MyCat 主要解決問題
海量數據保存 2。查詢優化
MyCat 對多數據庫的支持

MyCat 分片策略
MyCAT支持水平分片與垂直分片:水平分片:一個表格的數據分割到多個節點上,按照行分隔。垂直分片:一個數據庫中多個表格A,B,C,A存儲到節點1上,B存儲到節點2上,C存儲到節點3 上。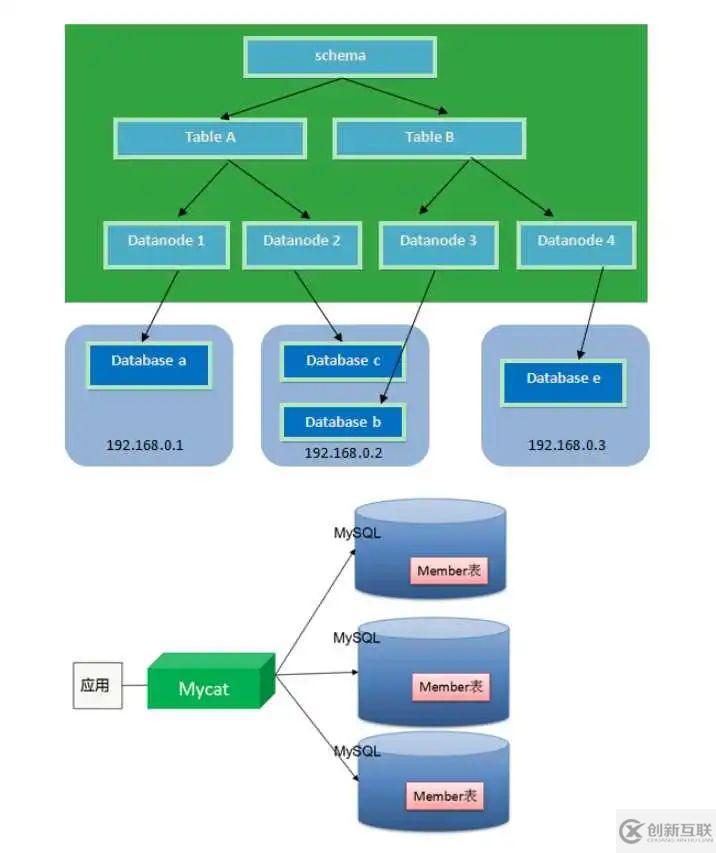
MyCAT通過定義表的分片規則來實現分片,每個表格可以捆綁一個分片規則,每個分片規則指定一個分 片字段并綁定一個函數,來實現動態分片算法。
Schema
Schema:邏輯庫,與MySQL中的Database(數據庫)對應,一個邏輯庫中定義了所包括的Table。
Table
Table:表,即物理數據庫中存儲的某一張表,與傳統數據庫不同,這里的表格需要聲明其所存儲的 邏輯數據節點DataNode。在此可以指定表的分片規則。
DataNode
DataNode:MyCAT的邏輯數據節點,是存放table的具體物理節點,也稱之為分片節點,通過 DataHost來關聯到后端某個具體數據庫上
DataHost
DataHost:定義某個物理庫的訪問地址,用于捆綁到Datanode上
MyCat 安裝
下載MyCat
wget http://dl.mycat.io/1.6-RELEASE/Mycat-server-1.6-RELEASE-20161028204710-
linux.tar.gz
解壓縮
tar -zxvf Mycat-server-1.6-RELEASE-20161028204710-linux.tar.gz
進入mycat/bin,啟動MyCat
- 啟動命令:./mycat start
- 停止命令:./mycat stop
- 重啟命令:./mycat restart
- 查看狀態:./mycat status
訪問MyCat
使用mysql的客戶端直接連接mycat服務。默認服務端口為【8066】
mysql -uroot -p123456 -h227.0.0.1 -P8066 MyCat 分片
配置schema.xml
什么是schema.xml
schema.xml作為Mycat中重要的配置文件之一,管理著Mycat的邏輯庫、表、分片規則、DataNode 以及DataHost之間的映射關系。弄懂這些配置,是正確使用Mycat的前提。schema 標簽用于定義MyCat實例中的邏輯庫 Table 標簽定義了MyCat中的邏輯表 dataNode 標簽定義了MyCat中的數據節點,也就是我們通常說所的數據分片。dataHost標簽在mycat邏輯庫中也是作為最底層的標簽存在,直接定義了具體的數據庫實例、讀 寫分離配置和心跳語句。
Schema.xml 配置
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<!--
schema : 邏輯庫 name:邏輯庫名稱
sqlMaxLimit:一次取多少條數據 要超過用limit xxx
table:邏輯表
dataNode:數據節點 對應datanode標簽
rule:分片規則,對應rule.xml
subTables:子表
primaryKey:分片主鍵 可緩存
-->
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100">
<!-- auto sharding by id (long) -->
配置Server.xml
server.xml介紹
server.xml幾乎保存了所有mycat需要的系統配置信息。最常用的是在此配置用戶名、密碼及權限。
server.xml配置
配置rule.xml
rule.xml里面就定義了我們對表進行拆分所涉及到的規則定義。我們可以靈活的對表使用不同的分片算
法,或者對表使用相同的算法但具體的參數不同。這個文件里面主要有tableRule和function這兩個標
簽。在具體使用過程中可以按照需求添加tableRule和function。
此配置文件可以不用修改,使用默認即可。
<table name="item" dataNode="dn1,dn2,dn3" rule="mod-long"
primaryKey="ID"/>
</schema>
<!-- <dataNode name="dn1$0-743" dataHost="localhost1" database="db$0-743"
/> -->
<dataNode name="dn1" dataHost="localhost1" database="db1" />
<dataNode name="dn2" dataHost="localhost1" database="db2" />
<dataNode name="dn3" dataHost="localhost1" database="db3" />
<!--
dataHost : 數據主機(節點主機)
balance:1 :讀寫分離 0 :讀寫不分離
writeType:0 第一個writeHost寫, 1 隨機writeHost寫
dbDriver:數據庫驅動 native:MySQL JDBC:Oracle、SQLServer
switchType:是否主動讀
1、主從自動切換 -1 不切換 2 當從機延時超過slaveThreshold值時切換為主讀
-->
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1"
slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="192.168.24.129:3306" user="root"
password="root" >
</writeHost>
</dataHost>
</mycat:schema>
配置server.xml
server.xml 介紹
server.xml幾乎保存了所有mycat需要的系統配置信息。最常用的是在此配置用戶名、密碼及權限。
server.xml 配置
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mycat:server SYSTEM "server.dtd">
<mycat:server xmlns:mycat="http://io.mycat/">
<system>
<property name="defaultSqlParser">druidparser</property>
</system>
<user name="mycat">
<property name="password">mycat</property>
<property name="schemas">TESTDB</property>
</user>
</mycat:server>
配置rule.xml
rule.xml里面就定義了我們對表進行拆分所涉及到的規則定義。我們可以靈活的對表使用不同的分片算 法,或者對表使用相同的算法但具體的參數不同。這個文件里面主要有tableRule和function這兩個標 簽。在具體使用過程中可以按照需求添加tableRule和function。此配置文件可以不用修改,使用默認即可
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mycat:rule SYSTEM "rule.dtd">
<mycat:rule xmlns:mycat=”http://io.mycat/“ >
<tableRule name="sharding-by-intfile">
<rule>
<columns>sharding_id</columns>
<algorithm>hash-int</algorithm>
</rule>
</tableRule>
<function name="hash-int"
class="io.mycat.route.function.PartitionByFileMap">
<property name="mapFile">partition-hash-int.txt</property>
</function>
</mycat:rule>
tableRule 標簽配置說明:
name 屬性指定唯一的名字,用于標識不同的表規則 rule 標簽則指定對物理表中的哪一列進行拆分和使用什么路由算法。columns 內指定要拆分的列名字。algorithm 使用 function 標簽中的 name 屬性。連接表規則和具體路由算法。當然,多個表規則 可以連接到同一個路由算法上。table 標簽內使用。讓邏輯表使用這個規則進行分片。
function 標簽配置說明:
name 指定算法的名字。class 制定路由算法具體的類名字。property 為具體算法需要用到的一些屬性。
幾個常用的分片規則
連續分片
日期列分區法
<!--按固定時間分片-->
<tableRule name="sharding-by-date">
<rule>
<columns>create_time</columns>
<algorithm>sharding-by-date</algorithm>
</rule>
</tableRule>
<function name="sharding-by-date"
class="io.mycat.route.function..PartitionByDate">
<property name="dateFormat">yyyy-MM-dd</property>
<property name="sBeginDate">2014-01-01</property>
<property name="sPartionDay">10</property>
</function>
<!--按自然月分片-->
<tableRule name="sharding-by-month">
<rule>
配置說明:
tableRule標簽:
columns :標識將要分片的表字段
algorithm :指定分片函數
function標簽:
dateFormat :日期格式
sBeginDate :開始日期
sPartionDay :分區天數,即默認從開始日期算起,分隔10天一個分區
二、范圍約定
配置說明:
tableRule標簽:
<columns>create_time</columns>
<algorithm>sharding-by-month</algorithm>
</rule>
</tableRule>
<function name="sharding-by-month"
class="io.mycat.route.function..PartitionByMonth">
<property name="dateFormat">yyyy-MM-dd</property>
<property name="sBeginDate">2014-01-01</property>
</function>
<!--
按單月小時分片
適合做日志,每月末,手工清理
-->
<tableRule name="sharding-by-hour">
<rule>
<columns>create_time</columns>
<algorithm>sharding-by-hour</algorithm>
</rule>
</tableRule>
<function name="sharding-by-hour"
class="io.mycat.route.function..LastestMonthPartition">
<property name="splitOneDay">24</property>
</function> 配置說明 tableRule標簽:columns :標識將要分片的表字段 algorithm :指定分片函數 function標簽:dateFormat :日期格式 sBeginDate :開始日期 sPartionDay :分區天數,即默認從開始日期算起,分隔10天一個分區
范圍約定
<tableRule name="auto-sharding-long">
<rule>
<columns>user_id</columns>
<algorithm>rang-long</algorithm>
</rule>
</tableRule>
<function name="rang-long"
class="io.mycat.route.function.AutoPartitionByLong">
<property name="mapFile">autopartition-long.txt</property>
</function>配置說明 tableRule標簽:columns :標識將要分片的表字段 algorithm :指定分片函數 function標簽:mapFile :指定分片函數需要的配置文件名稱
autopartition-long.txt文件內容:所有的節點配置都是從0開始,及0代表節點1,此配置非常簡單,即預先制定可能的id范圍對應某個分 片
# range start-end ,data node index
# K=1000,M=10000.
0-500M=0 0-100 0
500M-1000M=1 101-200 1
201-300 2
1000M-1500M=2
default=0
# 或以下寫法
# 0-10000000=0
# 10000001-20000000=1
優勢:擴容無需遷移數據 缺點:熱點數據,并發受限
離散分片
枚舉法
<tableRule name="sharding-by-intfile">
<rule>
<columns>user_id</columns>
<algorithm>hash-int</algorithm>
</rule>
</tableRule>
<function name="hash-int"
class="io.mycat.route.function.PartitionByFileMap">
<property name="mapFile">partition-hash-int.txt</property>
<property name="type">0</property>
<property name="defaultNode">0</property>
</function>
配置說明 tableRule標簽:columns :標識將要分片的表字段 algorithm :指定分片函數 function標簽:mapFile :指定分片函數需要的配置文件名稱 type :默認值為0,0表示Integer,非零表示String defaultNode :指定默認節點,小于0表示不設置默認節點,大于等于0表示設置默認節點,0代表節 點1。
默認節點的作用:枚舉分片時,如果碰到不識別的枚舉值,就讓它路由到默認節點。如果不配置默認節點(defaultNode值小于0表示不配置默認節點),碰到不識別的枚舉值 就會報錯:
partition-hash-int.txt 配置:
10000=0 列等于10000 放第一個分片
10010=1
男=0
女=1
beijing=0
tianjin=1
zhanghai=2
求模法
<tableRule name="mod-long">
<rule>
<columns>user_id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
<function name="mod-long"
class="io.mycat.route.function.PartitionByMod">
<!-- how many data nodes -->
<property name="count">3</property>
</function> tableRule標簽:columns :標識將要分片的表字段 algorithm :指定分片函數 function標簽:count :節點數量
一致性hash
<tableRule name="sharding-by-murmur">
<rule>
<columns>user_id</columns>
<algorithm>murmur</algorithm>
</rule>
</tableRule>
<function name="murmur"
class="io.mycat.route.function.PartitionByMurmurHash">
<!-- 默認是0 -->
<property name="seed">0</property>
<!-- 要分片的數據庫節點數量,必須指定,否則沒法分片 -->
<property name="count">2</property>
<!-- 一個實際的數據庫節點被映射為這么多虛擬節點,默認是160倍,也就是虛擬節點數是物理節點數
的160倍 -->
<property name="virtualBucketTimes">160</property>
<!-- <property name="weightMapFile">weightMapFile</property> 節點的權重,沒有指
定權重的節點默認是1。以properties文件的格式填寫,以從0開始到count-1的整數值也就是節點索引為
key,以節點權重值為值。所有權重值必須是正整數,否則以1代替 -->
<!-- <property name="bucketMapPath">/etc/mycat/bucketMapPath</property>
用于測試時觀察各物理節點與虛擬節點的分布情況,如果指定了這個屬性,會把虛擬節點的murmur
hash值與物理節點的映射按行輸出到這個文件,沒有默認值,如果不指定,就不會輸出任何東西 -->
</function>
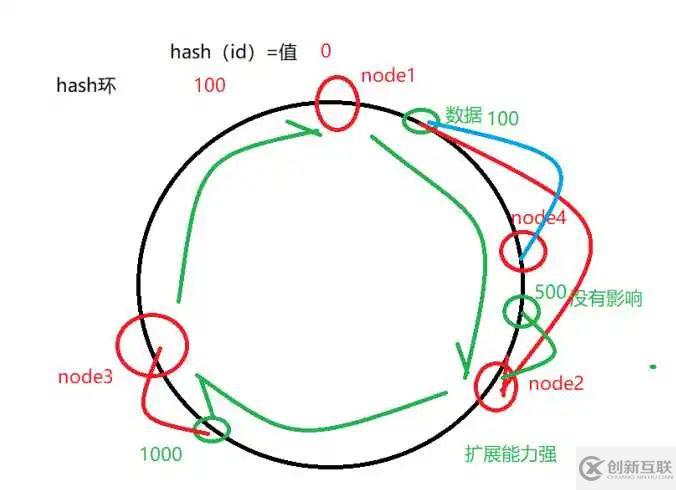
等,還有一些其他分片,這里,暫時不說明
測試分片
把商品表分片存儲到三個數據節點上。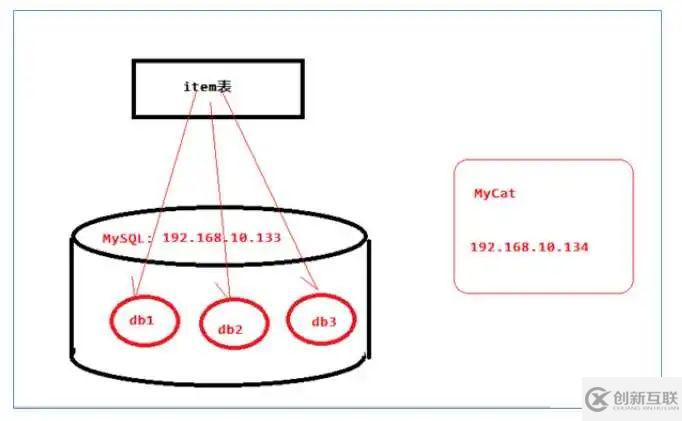
創建表
配置完畢后,重新啟動mycat。使用mysql客戶端連接mycat,創建表。
CREATE TABLE item (
id int(11) NOT NULL,
name varchar(20) DEFAULT NULL,
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 分片測試
分片策略指定為“auto-sharding-long” 分片規則指定為“mod-long”
到此,相信大家對“MyCat分片怎么配置”有了更深的了解,不妨來實際操作一番吧!這里是創新互聯網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
當前名稱:MyCat分片怎么配置
文章路徑:http://www.yijiale78.com/article18/ghdsdp.html
成都網站建設公司_創新互聯,為您提供移動網站建設、自適應網站、網站營銷、外貿建站、營銷型網站建設、網站排名
聲明:本網站發布的內容(圖片、視頻和文字)以用戶投稿、用戶轉載內容為主,如果涉及侵權請盡快告知,我們將會在第一時間刪除。文章觀點不代表本網站立場,如需處理請聯系客服。電話:028-86922220;郵箱:631063699@qq.com。內容未經允許不得轉載,或轉載時需注明來源: 創新互聯
