利用Python實現微信找房機器人實例教程-創新互聯
目的

兩年前曾為了租房做過一個找房機器人 「爬取豆瓣租房并定時推送到微信」,維護一段時間后就荒廢了。
當時因為代碼比較簡單一直沒開源,現在想想說不定開源后也能幫助一些同學更好的找到租房信息,所以簡單整理后,開源到 github,地址:https://github.com/facert/zufang (本地下載)
下面是當時寫的簡單原理介紹:
身在帝都的人都知道租房的困難,每次找房都是心力交瘁。其中豆瓣租房小組算是比較靠譜的房源了,但是由于小組信息繁雜,而且沒有搜索的功能,想要實時獲取租房信息是件很困難的事情,所以最近給自己挖了個坑,做個微信找房機器人,先看大概效果吧,見下圖:

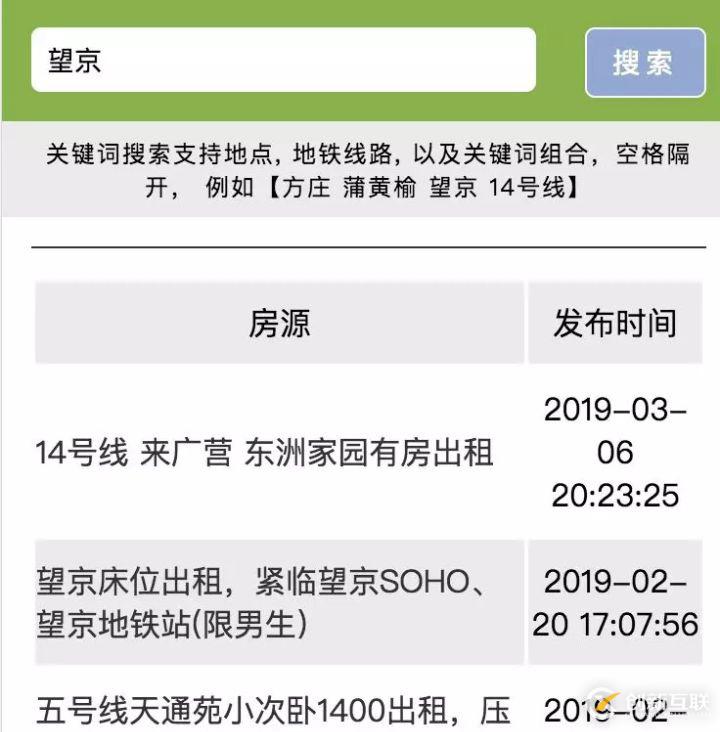
實現
說下大概的技術實現吧,首先是 scrapy 爬蟲對于豆瓣北京租房的小組實時爬取,并做了全文檢索,對 title, description 使用 jieba 和 whoosh 進行了分詞和索引,做成 api。接下來就是應用的接入,網上有微信機器人的開源 [wxBot](http://github.com/liuwons/wxBo),所以對它進行了修改, 實現了定時推送和持久化。最后順便把公眾號也做了同樣的功能,支持實時租房信息搜索。
部分代碼
scrapy 支持自定義 pipeline,能很方便的實現數據錄入的時候實時生成索引,見 code:
class IndexPipeline(object):
def __init__(self, index):
self.index = index
@classmethod
def from_crawler(cls, crawler):
return cls(
index=crawler.settings.get('WHOOSH_INDEX', 'indexes')
)
def process_item(self, item, spider):
self.writer = AsyncWriter(get_index(self.index, zufang_schema))
create_time = datetime.datetime.strptime(item['create_time'], "%Y-%m-%d %H:%M:%S")
self.writer.update_document(
url=item['url'].decode('utf-8'),
title=item['title'],
description=item['description'],
create_time=create_time
)
self.writer.commit()
return item另外有需要云服務器可以了解下創新互聯scvps.cn,海內外云服務器15元起步,三天無理由+7*72小時售后在線,公司持有idc許可證,提供“云服務器、裸金屬服務器、高防服務器、香港服務器、美國服務器、虛擬主機、免備案服務器”等云主機租用服務以及企業上云的綜合解決方案,具有“安全穩定、簡單易用、服務可用性高、性價比高”等特點與優勢,專為企業上云打造定制,能夠滿足用戶豐富、多元化的應用場景需求。
新聞標題:利用Python實現微信找房機器人實例教程-創新互聯
URL地址:http://www.yijiale78.com/article22/deoicc.html
成都網站建設公司_創新互聯,為您提供外貿建站、App開發、品牌網站建設、移動網站建設、網站營銷、網站排名
聲明:本網站發布的內容(圖片、視頻和文字)以用戶投稿、用戶轉載內容為主,如果涉及侵權請盡快告知,我們將會在第一時間刪除。文章觀點不代表本網站立場,如需處理請聯系客服。電話:028-86922220;郵箱:631063699@qq.com。內容未經允許不得轉載,或轉載時需注明來源: 創新互聯

- 詳談成都小程序開發的費用問題 2022-08-27
- 小程序開發需具備的思維方式 2016-03-13
- 微信小程序開發有哪些步驟要點 2021-04-27
- 開封小程序開發為什么定制版更好 2020-12-30
- 上海智能健康穿戴小程序開發有哪些優勢 2021-01-04
- 餐飲類成都小程序開發會給餐飲店帶來哪些幫助? 2022-07-07
- 企業是否一定要定制小程序開發? 2022-07-16
- 電商小程序開發總結 2021-02-04
- 小程序都有什么推廣方式? 2015-08-29
- 成都小程序開發:模板小程序沒效果是什么原因呢? 2022-08-01
- 成都小程序開發,教你制作信息反饋的小程序 2022-07-23
- 微信小程序開發用什么語言? 2022-08-02