python:scrapy學習demo分享-創新互聯
推薦一個比較容易上手的Python 框架scrapy。
讓客戶滿意是我們工作的目標,不斷超越客戶的期望值來自于我們對這個行業的熱愛。我們立志把好的技術通過有效、簡單的方式提供給客戶,將通過不懈努力成為客戶在信息化領域值得信任、有價值的長期合作伙伴,公司提供的服務項目有:域名與空間、網站空間、營銷軟件、網站建設、站前網站維護、網站推廣。開發環境搭建
Python安裝
下載地址:官網
這里我下載的是3.8.0的版本(我的安裝目錄是:D:\python\Python38-32)
安裝完后設置環境變量:在path中追加:D:\python\Python38-32; D:\python\Python38-32\Scripts
升級pip
輸入命令:
python -m pip install --upgrade pip
安裝scrapy依賴的模塊
安裝wheel
進入cmd執行命令命令:
> pip install wheel
安裝pywin32
下載地址:github
由于我安裝的Python是32位的,估選擇win32-py3.8版本,下載后雙擊安裝即可
安裝 lxml
運行命令:
> pip install lxml
安裝Twisted
由于直接使用命令在線安裝一直報下載超時,估采用離線安裝的方式
運行命令:
> pip install Twisted-19.10.0-cp38-cp38-win32.whl
安裝scrapy
運行命令:
> pip install scrapy
到目前為止就完成了scrapy環境的搭建,相對簡單
編寫demo
準備內容
被爬網站
選擇百度圖片首頁:http://image.baidu.com/
規則分析
首先想到的是通過xpath的方式來爬取圖片,xpath語句://div[@class=“imgrow”]/a/img/@src。但是在編寫爬蟲(Spiders)的時候發現http://image.baidu.com/請求并沒有將圖片的URL直接返回,而是通過后面的異步請求獲取,而且返回的是一個json字符串,估xpath方式行不通。
更換異步請求的URL為被爬網站:http://image.baidu.com/search/acjson?tn=resultjson_com&catename=pcindexhot&ipn=rj&ct=201326592&is=&fp=result&queryWord=&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&word=pcindexhot&face=0&istype=2&qc=&nc=1&fr=&pn=0&rn=30
創建scrapy項目 ImagesRename
運行命令:
> scrapy startproject ImagesRename
執行完后生成項目的目錄結構如圖:
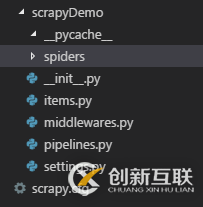
其中:
spiders目錄:用于放置爬蟲文件
items.py:用于保存所抓取的數據的容器,其存儲方式類似于 Python 的字典
pipelines.py:核心處理器,對爬取到的內容進行相應的操作,如:下載,保存等
settings.py:配置文件,修改USER_AGENT、存儲目錄等信息
scrapy.cfg:項目的配置文件
編寫item容器 items.py
import scrapy
class ImagesrenameItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
imgurl = scrapy.Field()
pass 鄭州專業婦科醫院 http://www.120zzzy.com/
創建蜘蛛文件ImgsRename.py
# -*- coding: utf-8 -*-
import scrapy
import json
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from ImagesRename.items import ImagesrenameItem
class ImgsRenameSpider(CrawlSpider):
name = 'ImgsRename'
allowed_domains = ['image.baidu.com']
#http://image.baidu.com/ 并沒有返回圖片鏈接,而是通過異步請求接口獲取的,爬取的URL必須是異步請求的鏈接
start_urls = ['http://image.baidu.com/search/acjson?tn=resultjson_com&catename=pcindexhot&ipn=rj&ct=201326592&is=&fp=result&queryWord=&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&word=pcindexhot&face=0&istype=2&qc=&nc=1&fr=&pn=0&rn=30',]
def parse(self, response):
# 實例化item
item = ImagesrenameItem()
#解析異步請求返回的json字符串
#經過分析需要的圖片鏈接保存在json——》data——》hoverURL
jsonString = json.loads(response.text)
data = jsonString["data"]
imgUrls = []
#循環將圖片URL保存到數組中
for d in data:
if d:
hov = d["hoverURL"]
imgUrls.append(hov)
item['imgurl'] = imgUrls
yield item
編寫核心處理器圖片下載中間件pipelines.py
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import re
from scrapy.pipelines.images import ImagesPipeline
from scrapy import Request
class ImagesrenamePipeline(ImagesPipeline):
def get_media_requests(self, item, info):
# 循環每一張圖片地址下載
for image_url in item['imgurl']:
#發起圖片下載的請求
yield Request(image_url)
修改配置文件settings.py
# -*- coding: utf-8 -*-
# Scrapy settings for ImagesRename project
BOT_NAME = 'ImagesRename'
SPIDER_MODULES = ['ImagesRename.spiders']
NEWSPIDER_MODULE = 'ImagesRename.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'ImagesRename (+http://www.yourdomain.com)'
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
ITEM_PIPELINES = {
'ImagesRename.pipelines.ImagesrenamePipeline': 300,
}
# 設置圖片存儲目錄
IMAGES_STORE = 'E:\圖片'
啟動程序下載圖片
運行命令:
scrapy crawl ImgsRename
到目前為止就已經完成了一個簡單的圖片爬取程序,結果如圖:
當然這些下載的文件名稱是一個隨機數,如果需要按照一個格式的文件名存儲則可以重新ImagesPipeline類的file_path方法即可,這里就不做詳細的介紹
名稱欄目:python:scrapy學習demo分享-創新互聯
網站URL:http://www.yijiale78.com/article38/csipsp.html
成都網站建設公司_創新互聯,為您提供全網營銷推廣、營銷型網站建設、網頁設計公司、品牌網站制作、網站維護、外貿建站
聲明:本網站發布的內容(圖片、視頻和文字)以用戶投稿、用戶轉載內容為主,如果涉及侵權請盡快告知,我們將會在第一時間刪除。文章觀點不代表本網站立場,如需處理請聯系客服。電話:028-86922220;郵箱:631063699@qq.com。內容未經允許不得轉載,或轉載時需注明來源: 創新互聯

- 理解透公司品牌內涵后才能做好品牌網站設計制作 2022-04-05
- 成都網站建設_品牌網站設計_網頁制作與開發 2023-02-15
- 品牌網站設計優越性提升企業建站水平 2021-04-18
- 品牌網站設計的意義是什么,如何起到這種效果? 2022-09-30
- 高端品牌網站設計注重的五大要素 2022-08-23
- 深圳福田網站設計與制作,品牌網站設計制作的步驟是什么? 2021-11-20
- 品牌網站設計怎樣做更加高端? 2022-11-15
- 深圳品牌網站設計公司 2014-05-13
- 常見的營銷網站類型你了解嗎 企業品牌網站設計思路 2021-05-11
- 品牌網站設計的四大原則 2022-12-12
- 品牌網站設計的流程有哪些 2023-02-13
- 品牌網站設計對企業來說有什么意義 2021-10-27