python簡單實現網絡爬蟲-創新互聯
? 在這一篇博客中,我會用python來實現一個簡單的網絡爬蟲。簡單的爬取一下一些音樂網站、小說網站的標題、關鍵字還有摘要!所以這個爬蟲并不是萬能爬,只針對符合特定規則的網站使用。(只使用于爬標題、關鍵字和摘要的,所以只能爬在head標簽中這三個信息都有的且meta標簽中name參數在本文信息前面的網站。)希望大家看了這篇博客,能對大家學習爬蟲有些幫助!(并不是很高深的爬蟲,很基礎!!!)
成都創新互聯公司堅持“要么做到,要么別承諾”的工作理念,服務領域包括:成都做網站、成都網站建設、企業官網、英文網站、手機端網站、網站推廣等服務,滿足客戶于互聯網時代的海滄網站設計、移動媒體設計的需求,幫助企業找到有效的互聯網解決方案。努力成為您成熟可靠的網絡建設合作伙伴!要用到的知識? 要用到的知識都是比較簡單的啦,基本上花點時間都能學會。
? 首先就是python的基礎語法啦,會用能看懂就好。(會有一些文件讀取的操作)
? 還有就是關于爬蟲的一些知識了:貪婪匹配和惰性匹配(re解析方式解析網頁源代碼)
? 還需要一丟丟前端的知識:只需要大概看得懂html源代碼就行(知道是在干嘛的)
? 這些就差不多了(b站是最好的大學(主要是我懶,也沒時間寫這些))
爬蟲的具體實現? 先拿一個網站做例子分析,打開酷狗官網,右鍵點擊檢查:
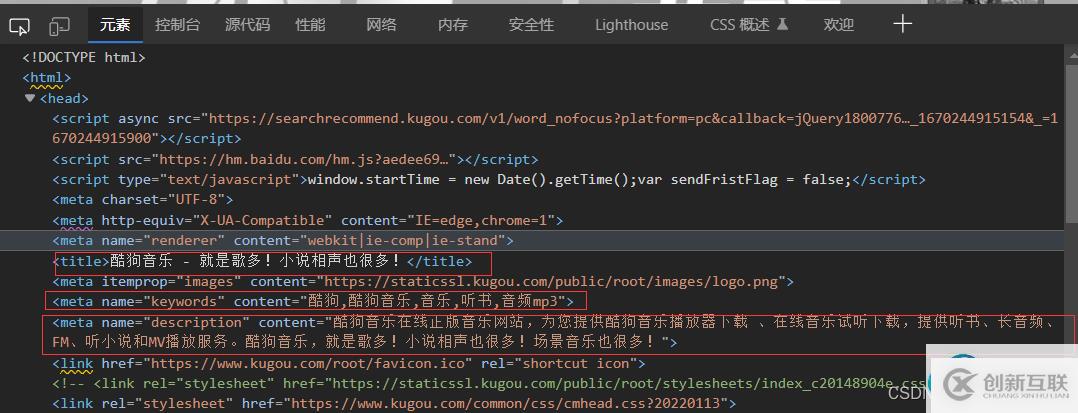
紅框中的就是我們需要提取的信息啦。這還是很容易提取出來的。使用re模塊里面的貪婪匹配與惰性匹配,將想要的數據提取出來就好。例如:
obj = re.compile(r'(?P.*?) .*?'
r'.*?)".*?>'
r'.*?)".*?>', re.S) 在上面我們只用了一次compile函數就完成了匹配。
? 但是我,我們需要提取的并不止是酷狗官網,還有其他一些網站。上面代碼寫的規則并不適合一些網站,比如,一些網站把標題放在最后面,關鍵字和摘要放在前面,那么我們就匹配不到想要的信息。這個也比較好解決,將一條compile拆成多條compile就行。
obj1 = re.compile(r'(?P.*?) ', re.S)
obj2 = re.compile(r'.*?)".*?>', re.S)
obj3 = re.compile(r'.*?)".*?>', re.S) ? 下面是整個python源代碼(在源代碼里面使用了文件讀取將提取到的信息保存到文件里面):
import requests
import re
import csv
urls = []
# 分別是酷狗音樂、酷我音樂、網易云音樂、起點中文網、咪咕音樂、bilibili、qq音樂
urls.append("https://www.kugou.com/")
urls.append("http://www.kuwo.cn/")
urls.append("https://music.163.com/")
urls.append("https://www.qidian.com/")
urls.append("https://www.migu.cn/index.html")
urls.append("https://www.bilibili.com/")
urls.append("https://y.qq.com/")
# 打開csv文件
f = open("test.csv", mode="w", encoding="utf-8")
csvwriter = csv.writer(f)
csvwriter.writerow(["標題","關鍵字","摘要"])
# 對所有網站進行get訪問,獲取源代碼后用re模塊將想要提取的內容提取出來
for url in urls:
# 向網頁發出請求
resp = requests.get(url)
# 設置字符編碼
resp.encoding = 'utf-8'
# 使用非貪婪匹配.*?(惰性匹配),re.S用來匹配換行符
obj1 = re.compile(r'(?P.*?) ', re.S)
obj2 = re.compile(r'.*?)".*?>', re.S)
obj3 = re.compile(r'.*?)".*?>', re.S)
# 對網頁源代碼進行匹配
result1 = obj1.finditer(resp.text)
result2 = obj2.finditer(resp.text)
result3 = obj3.finditer(resp.text)
# 創建一個隊列來將數據保存,方便寫入csv文件中
lis = []
for it in result1:
#print("標題:",it.group("title"))
lis.append(it.group("title"))
for it in result2:
#print("關鍵字:",it.group("keywords"))
lis.append(it.group("keywords"))
for it in result3:
#print("摘要:",it.group("description"))
lis.append(it.group("description"))
print(lis)
print()
# 將隊列寫入csv文件
csvwriter.writerow(lis)
# 關閉請求
resp.close()
print('over!')
# 關閉文件指針
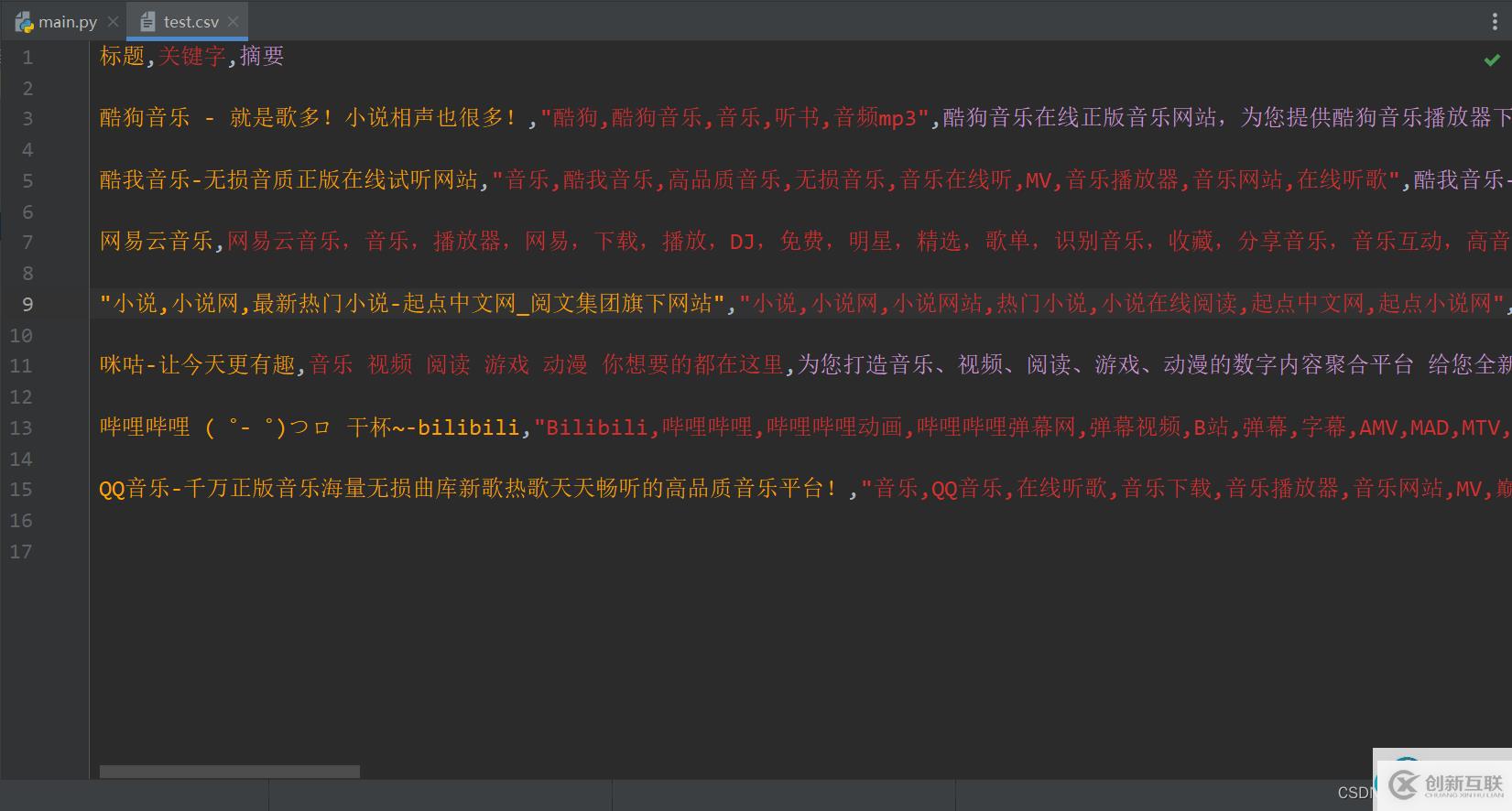
f.close() ? 下面是運行結果圖:

用WPS打開這個csv文件進行查看:?

在pycharm中打開csv文件查看是否將數據寫入文件中:
? 好矛盾好糾結,又想把思路寫清楚又感覺沒必要。。。。。。
? 感謝瀏覽這篇博客,希望這篇博客的內容能對你有幫助。
你是否還在尋找穩定的海外服務器提供商?創新互聯www.cdcxhl.cn海外機房具備T級流量清洗系統配攻擊溯源,準確流量調度確保服務器高可用性,企業級服務器適合批量采購,新人活動首月15元起,快前往官網查看詳情吧
本文標題:python簡單實現網絡爬蟲-創新互聯
文章URL:http://www.yijiale78.com/article4/cspcoe.html
成都網站建設公司_創新互聯,為您提供營銷型網站建設、商城網站、移動網站建設、網站制作、網站導航、軟件開發
聲明:本網站發布的內容(圖片、視頻和文字)以用戶投稿、用戶轉載內容為主,如果涉及侵權請盡快告知,我們將會在第一時間刪除。文章觀點不代表本網站立場,如需處理請聯系客服。電話:028-86922220;郵箱:631063699@qq.com。內容未經允許不得轉載,或轉載時需注明來源: 創新互聯

- 網站建設的時候應該選擇靜態頁面還是動態頁面 2016-10-30
- 動態網站與靜態網站的區別在哪里? 2022-04-28
- 創新互聯:什么是動態網站?動態網站與靜態網站如何區別 2022-05-21
- 偽靜態和靜態頁面哪一個更好 2016-11-02
- 網站建設中開發使用靜態網站和動態網站哪個制作比較好? 2020-12-06
- 靜態網站與動態網站之間的區別 2022-06-05
- 網站生成靜態頁面是不是會更好? 2016-03-07
- 靜態網站跟動態網站在制作上有哪些區別呢 2016-11-12
- 動態網站與靜態網站哪種有助于排名 2016-11-11
- 成都SEO:關于網站URL偽靜態的好處及對網站優化的影響 2016-11-15
- 靜態網頁的設計及發展 2016-11-10
- 談談網站建設靜態網站與動態網站的區別-網站建設創新互聯科技 2021-09-27