Python3如何解決讀取中文文件txt編碼的問題-創新互聯
小編給大家分享一下Python3如何解決讀取中文文件txt編碼的問題,相信大部分人都還不怎么了解,因此分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后大有收獲,下面讓我們一起去了解一下吧!

問題描述
嘗試用Python寫一個Wordcloud的時候,出現了編碼問題。
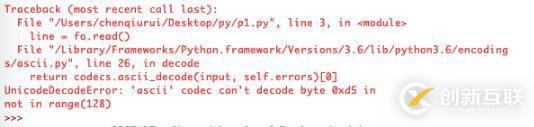
照著網上某些博客的說法添添改改后,結果是變成了“UnicodeDecodeError: ‘utf-8' codec can't decode byte…”這個錯誤。
搗鼓了一天啊,TXT(此處為本人現下內心表情)。最后,干脆寫個最簡單的文件讀取,竟然還是報錯。于是就考慮是不是txt的編碼問題,因為讀取的txt文件是在Mac上面新建的純文本文件,一時沒找到在哪里查看編碼,最后拷貝到Windows系統上,查看了txt文件的編碼,竟然是ASCII,不是我最愛的utf-8,Mac你辜負了我對你的一番信任啊!ε(┬┬﹏┬┬)3
解決方法
將txt文件的編碼格式改為utf-8即可
此外,在打開文件的時候,要加上第三個參數encoding=‘utf8'(沒有橫杠)。
with open('./test3.txt','r',encoding='utf8') as fin:
for line in fin.readlines():
line = line.strip('\n')下面附上第一次成功顯示的詞云的源碼(參考網上他人的,注釋很詳細)
import jieba
import jieba.analyse
from matplotlib import pyplot as plt
from scipy.misc import imread
from wordcloud import WordCloud,STOPWORDS,ImageColorGenerator
# 1.讀取數據
with open("./test.txt","r",encoding="utf8") as f:
text = f.read()
# 2.基于 TextRank 算法的關鍵詞抽取,top50
keywords = jieba.analyse.textrank(text, topK=50, withWeight=False, allowPOS=('ns', 'n', 'vn', 'v'))
file = ",".join(keywords)
# 指定中文字體,不然中文顯示框框
font = r'./HYQiHei-25J.ttf'
print(file)
# 指定背景圖,隨意
image = imread('cake.jpg')
wc = WordCloud(
font_path=font,
background_color='white',#背景色
mask=image,#背景圖
stopwords=STOPWORDS,#設置停用詞
max_words=100,#設置大文字數
max_font_size=100,#設置大字體
width=800,
height=1000,
)
#生成詞云
image_colors = ImageColorGenerator(image)
wc.generate(file)
# 使用matplotlib,顯示詞云圖
plt.imshow(wc) #顯示詞云圖
plt.axis('off') #關閉坐標軸
plt.show()
# 保存圖片
wc.to_file('news.png')
以上是“Python3如何解決讀取中文文件txt編碼的問題”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注創新互聯行業資訊頻道!
名稱欄目:Python3如何解決讀取中文文件txt編碼的問題-創新互聯
文章分享:http://www.yijiale78.com/article4/psgoe.html
成都網站建設公司_創新互聯,為您提供網站設計、品牌網站設計、企業建站、虛擬主機、搜索引擎優化、網站改版
聲明:本網站發布的內容(圖片、視頻和文字)以用戶投稿、用戶轉載內容為主,如果涉及侵權請盡快告知,我們將會在第一時間刪除。文章觀點不代表本網站立場,如需處理請聯系客服。電話:028-86922220;郵箱:631063699@qq.com。內容未經允許不得轉載,或轉載時需注明來源: 創新互聯

- 外貿建站之營銷型網站 2016-03-26
- 海珠區外貿建站公司:專注歐美英文網頁設計制作! 2016-02-07
- 越秀區小北路外貿建站,越秀區小北路外貿網站建設公司 2016-04-06
- 外貿建站選美國空間還是香港空間好? 2022-10-10
- 外貿建站選擇香港主機都有哪些優勢? 2022-10-10
- 外貿建站是否應該選擇響應式網站設計? 2015-12-18
- 外貿建站推廣怎么做效果最好? 2016-03-23
- 自助外貿建站不等于企業網站建設 2016-03-19
- 開發好的APP如何獲取用戶,告訴你了你也不一定領悟明白! 2022-06-02
- 什么是外貿建站?建站前都有哪些必須了解的? 2015-08-19
- 成都外貿建站公司哪家好? 2015-03-21
- 外貿建站零基礎——搭建網站 2022-12-22