處理哈希沖突的線性探測法-創新互聯
哈希表,是根據關鍵字(Key value)而直接訪問在內存存儲位置的數據結構。也就是說,它通過計算一個關于鍵值的函數,將所需查詢的數據映射到表中一個位置來訪問記錄,這加快了查找速度。這個映射函數稱做散列函數,存放記錄的數組稱做散列表。(摘自維基百科)

對不同的關鍵字可能得到同一散列地址,即k1!=k2,而f(k1)=f(k2),這種現象稱為碰撞(英語:Collision),也叫哈希沖突。
處理哈希沖突的方法有很多種:
閉散列法
開鏈法(哈希桶)
素數表
字符串哈希算法
在這里我們討論最簡單的閉散列法的線性探測法,學會了這種方法,就可以在線性探測法的思想基礎上領會其他方法。
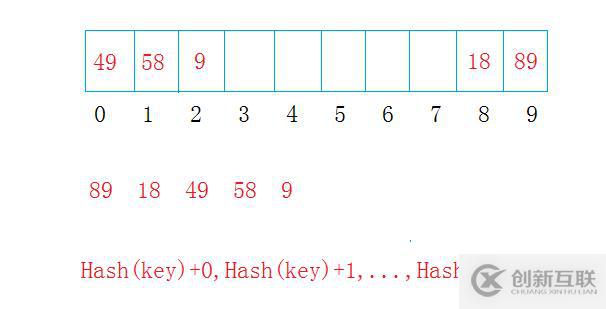
線性探測法
定義:通過散列函數hash(key),找到關鍵字key在線性序列中的位置,如果當前位置已經有了一個關鍵字,就長生了哈希沖突,就往后探測i個位置(i小于線性序列的大小),直到當前位置沒有關鍵字存在。
#pragma once
#include<iostream>
#include<string>
using namespace std;
enum State
{
EMPTY,
EXIST,
DELETE
};
template<class T>
struct DefaultFunc
{
size_t operator()(const T& data)
{
return (size_t)data;
}
};
struct StringFunc
{
size_t operator()(const string& str)
{
size_t sum = 0;
for (size_t i = 0; i < str.size(); ++i)
{
sum += str[i];
}
return sum;
}
};
template<class K,class FuncModel=DefaultFunc<K>>
class HashTable
{
public:
HashTable();
HashTable(const size_t size);
bool Push(const K& data);//增
bool Remove(const K& data);//刪
size_t Find(const K& data);//查
bool Alter(const K& data, const K& newdata);//改
void Print();//打印哈希表
protected:
size_t HashFunc(const K& data);//散列函數(哈希函數)
void Swap(HashTable<K, FuncModel>& x);
protected:
K* _table;//哈希表
State* _state;//狀態表
size_t _size;
size_t _capacity;
FuncModel _HF;//區分默認類型的哈希函數和string類型的哈希函數
};.cpp文件
#define _CRT_SECURE_NO_WARNINGS 1
#include"HashTable.h"
template<class K, class FuncModel = DefaultFunc<K>>
HashTable<K, FuncModel>::HashTable()
:_table(NULL)
, _state(NULL)
, _size(0)
, _capacity(0)
{}
template<class K, class FuncModel = DefaultFunc<K>>
HashTable<K, FuncModel>::HashTable(const size_t size)
:_table(new K[size])
, _state(new State[size])
, _size(0)
, _capacity(size)
{
//這里別用memset()來初始化_state,對于枚舉類型的動態內存不能用memset初始化
//老老實實一個一個初始化
for (size_t i = 0; i < _capacity; i++)
{
_state[i] = EMPTY;
}
}
template<class K, class FuncModel = DefaultFunc<K>>
size_t HashTable<K, FuncModel>::HashFunc(const K& data)
{
return _HF(data)%_capacity;//Mod哈希表的容量,找到在哈希表中的位置,
//其實在這里最好Mod一個素數
}
template<class K, class FuncModel = DefaultFunc<K>>
void HashTable<K, FuncModel>::Swap(HashTable<K, FuncModel>& x)//交換兩個哈希表
{
swap(_table, x._table);
swap(_state, x._state);
swap(_size, x._size);
swap(_capacity, x._capacity);
}
template<class K, class FuncModel = DefaultFunc<K>>
bool HashTable<K, FuncModel>::Push(const K& data)
{
if if (_size *10 >= _capacity* 8)//載荷因子不超過0.8
{
HashTable<K, FuncModel> tmp(2 * _capacity + 2);
for (size_t i = 0; i < _capacity; ++i)
{
if (_state[i] == EXIST)
{
size_t index = HashFunc(_table[i]);
while (tmp._state[index] == EXIST)
{
index++;
}
tmp._table[index] = _table[i];
tmp._state[index] = EXIST;
}
}
Swap(tmp);
}
size_t index = HashFunc(data);
while (_state[index] == EXIST)
{
index++;
}
_table[index] = data;
_state[index] = EXIST;
_size++;
return true;
}
template<class K, class FuncModel = DefaultFunc<K>>
void HashTable<K, FuncModel>::Print()
{
for (size_t i = 0; i < _capacity; ++i)
{
if (_state[i] == EXIST)
{
printf("_table[%d]:", i);
cout << _table[i] << "->存在";
}
else if (_state[i] == DELETE)
{
printf("_table[%d]:", i);
cout << _table[i] << "->刪除";
}
else
{
printf("_table[%d]:空", i);
}
cout << endl;
}
}
template<class K, class FuncModel = DefaultFunc<K>>
bool HashTable<K, FuncModel>::Remove(const K& data)
{
if (_size > 0)
{
size_t index = Find(data);
if (index > 0)
{
_state[index] = DELETE;
_size--;
return true;
}
else
return false;
}
return false;
}
template<class K, class FuncModel = DefaultFunc<K>>
size_t HashTable<K, FuncModel>::Find(const K& data)
{
size_t index = HashFunc(data);
size_t time = _capacity;
while (time--)
{
if (_table[index++] == data)
{
return --index;
}
if (index == _capacity)
{
index = 0;
}
}
return -1;
}
template<class K, class FuncModel = DefaultFunc<K>>
bool HashTable<K, FuncModel>::Alter(const K& data, const K& newdata)
{
size_t index = Find(data);
if (index > 0)
{
_state[index] = DELETE;
if (Push(newdata))
return true;
else
return false;
}
return false;
}在實現過程中要注意的問題有以下幾點:
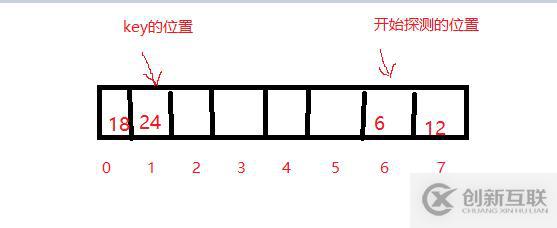
對于線性探測來說,有時候會遇到一開始探測的位置就在哈希table的最后的部分,但是因為哈希沖突key值被沖突到了哈希table的最前部分,所以探測到了table尾后將index置為0,簡單又粗暴。
對于對哈希表中的數據的刪除是屬于弱刪除,也就是說刪除并沒有刪除數據,只是把數據的狀態_state置為DELETE。
當載荷因子超過0.8時就得增容,載荷因子越高哈希沖突越多,不命中率越高。CPU緩存會大大升高。載荷因子a=填入表中元素的個數/散列表長度。
對代碼的兩點說明:
在這里我將模板聲明與定義分開,涉及了模板的分離編譯,對模板分離編譯還不太清楚的可以查看博主博客http://helloleex.blog.51cto.com/10728491/1769994
并且為了增強代碼的復用性,我使用了仿函數來區別調用默認類型(基本類型,自定義類型)和string類型,使調用更加靈活
另外有需要云服務器可以了解下創新互聯scvps.cn,海內外云服務器15元起步,三天無理由+7*72小時售后在線,公司持有idc許可證,提供“云服務器、裸金屬服務器、高防服務器、香港服務器、美國服務器、虛擬主機、免備案服務器”等云主機租用服務以及企業上云的綜合解決方案,具有“安全穩定、簡單易用、服務可用性高、性價比高”等特點與優勢,專為企業上云打造定制,能夠滿足用戶豐富、多元化的應用場景需求。
標題名稱:處理哈希沖突的線性探測法-創新互聯
本文URL:http://www.yijiale78.com/article40/pijeo.html
成都網站建設公司_創新互聯,為您提供用戶體驗、網站內鏈、外貿建站、軟件開發、定制網站、App設計
聲明:本網站發布的內容(圖片、視頻和文字)以用戶投稿、用戶轉載內容為主,如果涉及侵權請盡快告知,我們將會在第一時間刪除。文章觀點不代表本網站立場,如需處理請聯系客服。電話:028-86922220;郵箱:631063699@qq.com。內容未經允許不得轉載,或轉載時需注明來源: 創新互聯

- 外貿建站過程中一些問題以及應該注意什么 2015-07-07
- 外貿建站9大注意要點 2015-10-03
- 外貿建站完成后如何繼續完善 2021-08-25
- 詮釋網站排名的高低與流量多少之間的關系 2022-06-24
- 外貿建站不得不說的秘密 2015-05-07
- 外貿建站應該怎么做 2021-03-05
- 創新互聯電商外貿建站的優勢! 2015-04-20
- 外貿建站推廣?八大技巧幫您引流 2016-03-01
- 為什么要選擇外貿建站? 2015-04-27
- 深圳網站建設之外貿建站原則 2015-10-26
- 外貿建站過程中 這些點你必須了解 2015-10-03
- 按外貿建站域名五原則挑選老外喜歡的域名 2015-05-01