PostgreSQL中怎么實現遞歸查詢-創新互聯
本篇文章給大家分享的是有關PostgreSQL中怎么實現遞歸查詢,小編覺得挺實用的,因此分享給大家學習,希望大家閱讀完這篇文章后可以有所收獲,話不多說,跟著小編一起來看看吧。
創新互聯是一家集網站建設,哈巴河企業網站建設,哈巴河品牌網站建設,網站定制,哈巴河網站建設報價,網絡營銷,網絡優化,哈巴河網站推廣為一體的創新建站企業,幫助傳統企業提升企業形象加強企業競爭力。可充分滿足這一群體相比中小企業更為豐富、高端、多元的互聯網需求。同時我們時刻保持專業、時尚、前沿,時刻以成就客戶成長自我,堅持不斷學習、思考、沉淀、凈化自己,讓我們為更多的企業打造出實用型網站。在內部,它是這樣表示滴:
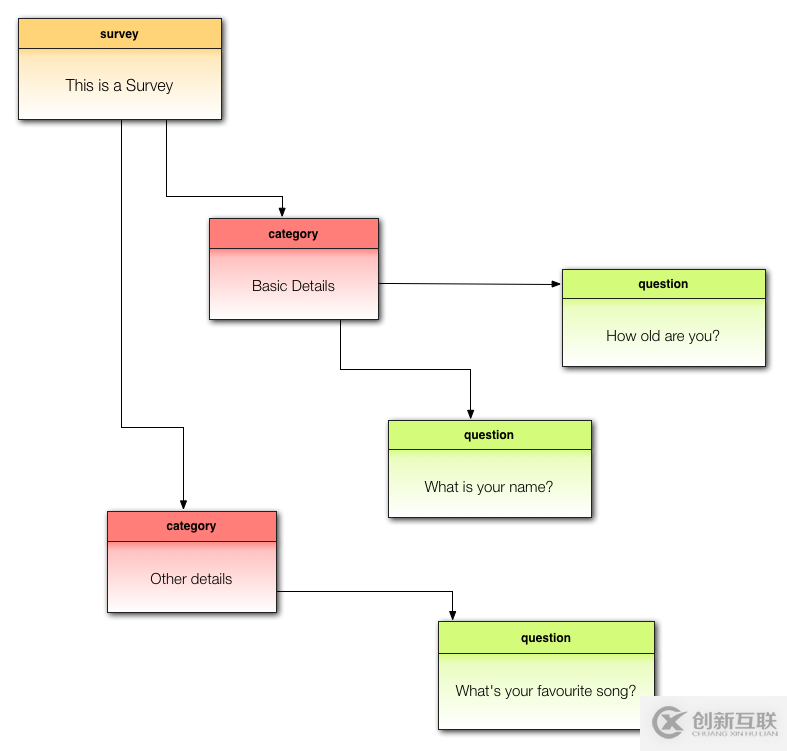
一個調查包括了許多問題(question)。一系列問題可以歸到(可選)一個分類(category)中。我們實際的數據結構會復雜一點(特別是子問題sub-question部分),但先當它就只有question跟category吧。
我們是這樣保存question跟category的。
每個question和category都有一個order_number字段。是個整型,用來指定它自己與其它兄弟的相對關系。
舉個例子,比如對于上面這個調查:
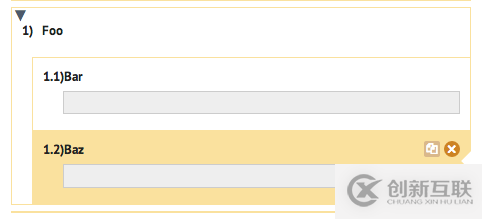
Bar的order_number比Baz的小。
這樣一個分類下的問題就能按正確的順序出現:
# In category.rb
def sub_questions_in_order
questions.order('order_number')
end實際上一開始我們就是這樣fetch整個調查的。每個category會按順序獲取到全部其下的子問題,依此類推遍歷整個實體樹。
這就給出了整棵樹的深度優先的順序:
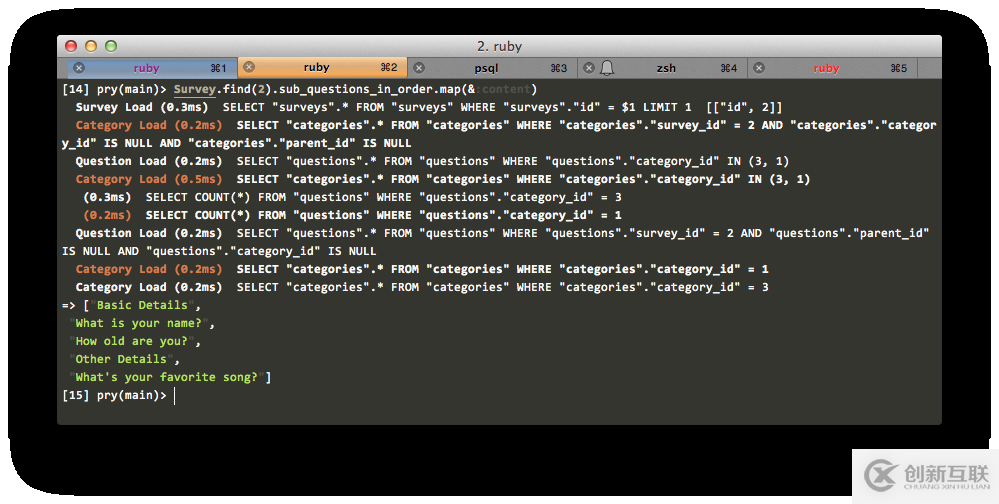
對于有5層以上的內嵌、多于100個問題的調查,這樣搞跑起來奇慢無比。
遞歸查詢
哥也用過那些awesome_nested_set之類的gem,但據我所知,它們沒一個是支持跨多model來fetch的。
后來哥無意中發現了一個文檔說PostgreSQL有對遞歸查詢的支持!唔,這個可以有。
那就試下用遞歸查詢搞搞這個問題吧(此時哥對它的了解還很水,有不到位,勿噴)。
要在Postgres做遞歸查詢,得先定義一個初始化查詢,就是非遞歸部分。
本例里,就是最上層的question跟category。最上層的元素不會有父分類,所以它們的category_id是空的。
( SELECT id, content, order_number, type, category_id FROM questions WHERE questions.survey_id = 2 AND questions.category_id IS NULL ) UNION ( SELECT id, content, order_number, type, category_id FROM categories WHERE categories.survey_id = 2 AND categories.category_id IS NULL )
(這個查詢和接下來的查詢假定要獲取的是id為2的調查)
這就獲取到了最上層的元素。
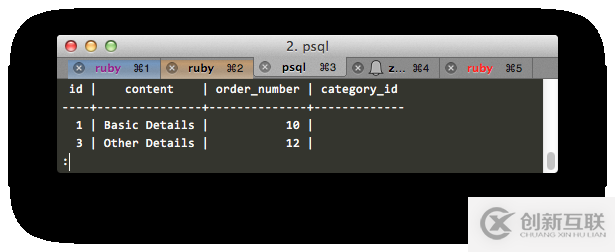
下面要寫遞歸的部分了。根據下面這個Postgres文檔:

遞歸部分就是要獲取到前面初始化部分拿到的元素的全部子項。
WITH RECURSIVE first_level_elements AS ( -- Non-recursive term ( ( SELECT id, content, order_number, category_id FROM questions WHERE questions.survey_id = 2 AND questions.category_id IS NULL UNION SELECT id, content, order_number, category_id FROM categories WHERE categories.survey_id = 2 AND categories.category_id IS NULL ) ) UNION -- Recursive Term SELECT q.id, q.content, q.order_number, q.category_id FROM first_level_elements fle, questions q WHERE q.survey_id = 2 AND q.category_id = fle.id ) SELECT * from first_level_elements;
等等,遞歸部分只能獲取question。如果一個子項的第一個子分類是個分類呢?Postgres不給引用非遞歸項超過一次。所以在question跟category結果集上做UNION是不行的。這里得搞個改造一下:
WITH RECURSIVE first_level_elements AS ( ( ( SELECT id, content, order_number, category_id FROM questions WHERE questions.survey_id = 2 AND questions.category_id IS NULL UNION SELECT id, content, order_number, category_id FROM categories WHERE categories.survey_id = 2 AND categories.category_id IS NULL ) ) UNION ( SELECT e.id, e.content, e.order_number, e.category_id FROM ( -- Fetch questions AND categories SELECT id, content, order_number, category_id FROM questions WHERE survey_id = 2 UNION SELECT id, content, order_number, category_id FROM categories WHERE survey_id = 2 ) e, first_level_elements fle WHERE e.category_id = fle.id ) ) SELECT * from first_level_elements;
在與非遞歸部分join之前就將category和question結果集UNION了。
這就產生了所有的調查元素:
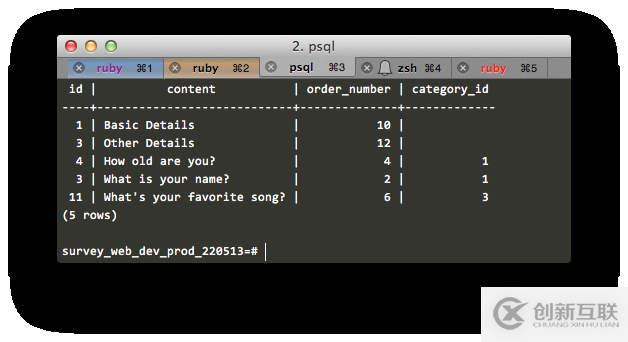
不幸的是,順序好像不對。
在遞歸查詢內排序
這問題出在雖然有效的為一級元素獲取到了全部二級元素,但這做的是廣度優先的查找,實際上需要的是深度優先。
這可怎么搞呢?
Postgres有能在查詢時建array的功能。
那就就建一個存放fetch到的元素的序號的array吧。將這array叫做path好了。一個元素的path就是:
父分類的path(如果有的話)+自己的order_number
如果用path對結果集排序,就可以將查詢變成深度優先的啦!
WITH RECURSIVE first_level_elements AS ( ( ( SELECT id, content, category_id, array[id] AS path FROM questions WHERE questions.survey_id = 2 AND questions.category_id IS NULL UNION SELECT id, content, category_id, array[id] AS path FROM categories WHERE categories.survey_id = 2 AND categories.category_id IS NULL ) ) UNION ( SELECT e.id, e.content, e.category_id, (fle.path || e.id) FROM ( SELECT id, content, category_id, order_number FROM questions WHERE survey_id = 2 UNION SELECT id, content, category_id, order_number FROM categories WHERE survey_id = 2 ) e, first_level_elements fle WHERE e.category_id = fle.id ) ) SELECT * from first_level_elements ORDER BY path;
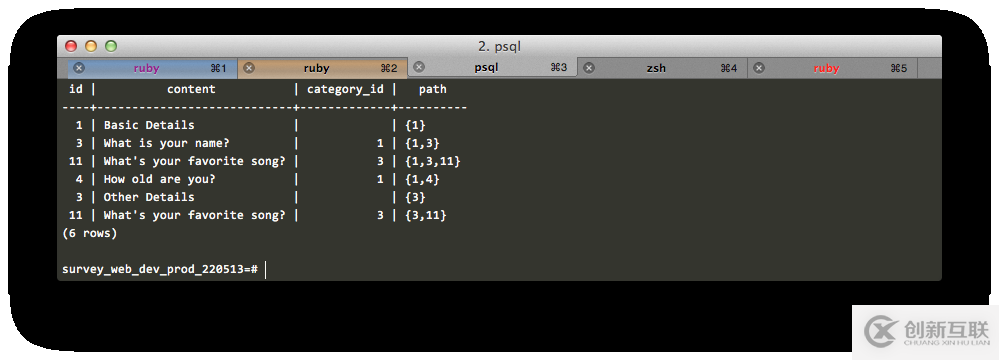
這很接近成功了。但有兩個 What's your favourite song?
這是由比較ID來查找子項引起的:
WHERE e.category_id = fle.id
fle同時包含question和category。但需要的是只匹配category(因為question不會有子項)。
那就給每個這樣的查詢硬編碼一個類型(type)吧,這樣就不用試著檢查question有沒有子項了:
WITH RECURSIVE first_level_elements AS ( ( ( SELECT id, content, category_id, 'questions' as type, array[id] AS path FROM questions WHERE questions.survey_id = 2 AND questions.category_id IS NULL UNION SELECT id, content, category_id, 'categories' as type, array[id] AS path FROM categories WHERE categories.survey_id = 2 AND categories.category_id IS NULL ) ) UNION ( SELECT e.id, e.content, e.category_id, e.type, (fle.path || e.id) FROM ( SELECT id, content, category_id, 'questions' as type, order_number FROM questions WHERE survey_id = 2 UNION SELECT id, content, category_id, 'categories' as type, order_number FROM categories WHERE survey_id = 2 ) e, first_level_elements fle -- Look for children only if the type is 'categories' WHERE e.category_id = fle.id AND fle.type = 'categories' ) ) SELECT * from first_level_elements ORDER BY path;
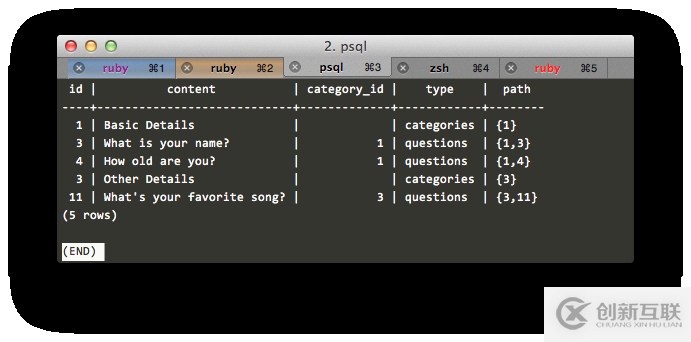
這看起來就ok了。搞定!
下面就看看這樣搞的性能如何。
用下面這個腳本(在界面上創建了一個調查之后),哥生成了10個子問題序列,每個都有6層那么深。
survey = Survey.find(9) 10.times do category = FactoryGirl.create(:category, :survey => survey) 6.times do category = FactoryGirl.create(:category, :category => category, :survey => survey) end FactoryGirl.create(:single_line_question, :category_id => category.id, :survey_id => survey.id) end
每個問題序列看起來是這樣滴:

那就來看看遞歸查詢有沒有比一開始的那個快一點吧。
pry(main)> Benchmark.ms { 5.times { Survey.find(9).sub_questions_using_recursive_queries }}
=> 36.839999999999996
pry(main)> Benchmark.ms { 5.times { Survey.find(9).sub_questions_in_order } }
=> 1145.1309999999999以上就是PostgreSQL中怎么實現遞歸查詢,小編相信有部分知識點可能是我們日常工作會見到或用到的。希望你能通過這篇文章學到更多知識。更多詳情敬請關注創新互聯行業資訊頻道。
當前題目:PostgreSQL中怎么實現遞歸查詢-創新互聯
分享鏈接:http://www.yijiale78.com/article42/cegcec.html
成都網站建設公司_創新互聯,為您提供ChatGPT、網站建設、小程序開發、電子商務、品牌網站建設、自適應網站
聲明:本網站發布的內容(圖片、視頻和文字)以用戶投稿、用戶轉載內容為主,如果涉及侵權請盡快告知,我們將會在第一時間刪除。文章觀點不代表本網站立場,如需處理請聯系客服。電話:028-86922220;郵箱:631063699@qq.com。內容未經允許不得轉載,或轉載時需注明來源: 創新互聯

- 網頁設計提高用戶體驗設計之用戶執行任務中減少重復操作 2022-05-26
- 網站如何布局利用SEO優化符合用戶體驗 2023-01-30
- 網站導航如何設計可以提高用戶體驗 2022-11-24
- 網站建設提升用戶體驗,靠的不僅僅是設計 2016-11-07
- 優秀的用戶體驗設計可以提高網站轉化率 2016-08-10
- 用戶體驗度的參考量有哪些 2021-07-02
- 提升網站建設用戶體驗的有效實際方法 2013-12-26
- 選擇正確的關鍵詞定位,可快速增加用戶體驗度 2023-04-16
- 網站制作中如何增進用戶體驗度 2021-08-31
- 網站建設中四點做好用戶體驗 2016-11-04
- 網站優化之怎樣把用戶體驗做得更好 2022-06-25
- 愛前端,愛生活,專注前端開發,關注用戶體驗_創新互聯前端開發工程師蘇凡 2021-04-18